Ceph
Ceph Deployment
![]()
All of our components are deployed and managed with a puppet module forked from a module started by the Openstack group.
The module code is available on Github: https://github.com/MI-OSiRIS/puppet-ceph
The README included in the Github repository covers module usage. It has been updated to reflect our changes since the fork.
Ceph Monitor Settings
You can set these in /etc/ceph/ceph.conf under the [mon] section.
For a larger clusters the recommendation is to use more RAM for the monitor RocksDB cache. We also cache a larger number of OSD map under the theory that more is better here as far as avoiding slower disk storage (though our monitor VMs reside on NVMe devices). These settings are referenced in the Ceph 13.2.3 release notes.
rocksdb_cache_size = 1073741824 # default is 536870912 mon_osd_cache_size = 1000 # default is 500
We also set longer lease timeouts because we had some occurences under heavy load where monitors were constantly being forced into elections due to timeouts on lease acknowledgements. These may no longer be necessary due to other optimizations (caching, recovery throttling) but in a deployment with higher latency between monitor instances there may be more potential to still get into situations where the monitors are having lease timeout issues.
mon_lease = 10 mon_lease_renew_interval = 7 mon_lease_ack_timeout = 20
We set OSD reporter limits higher to to match our cluster size and crush tree. Subtree limit means that ceph will not automatically mark out a whole host or a whole site even if all the osd are down - typically such a condition indicates that the OSD are fine but a host or site is down for repair, network issue, etc. We don’t want to mark out and have to again replicate the data when it comes back up. Our sites are referred to as ‘member’ in the CRUSH tree.
mon_osd_down_out_subtree_limit = 'member', mon_osd_min_down_reporters = 5 # recommended to set to 3 or 5 for larger clusters - default is 1
Our provisioning system creates several small-PG count new pools for virtual orgs in OSiRIS (we later increase PG counts depending on usage). As a result there is a large skew between the number of objects per-PG in our different pools. We set the skew higher than the default so we do not get warnings about it.
mon_pg_warn_max_object_skew = 15
Note: You can review available monitor settings using the ‘ceph daemon’ command.
ceph daemon mon.yourmon config show
Ceph Recovery Throttling
Although not currently the case we did for the first several years of the project have network links between our sites that were not equal in bandwidth. In particular we had one site linked with only 10Gbit vs 80 between the other two.
One obvious effect is that our maximum cluster IO capability is restricted to that of the slowest link - every write has to replicate over that link and some OSD will be used for reads via that link. There’s not much we can do about this if we want replication to each OSiRIS site.
Another effect is that recovery and backfill operations can saturate the slowest link to the point of effecting cluster stability. Recovery is when Ceph loses a data replica and has to copy to make a new replica. Backfill is when a new replica destination is added (such as a new host) and Ceph now needs to balance replicas onto that destination. There may be some network quality of service options to alleviate this now being explored by our NMAL component but there are also some things we can do to throttle back Ceph recovery/backfill.
After some experimentation we arrived at these settings which reduced the backfill/recovery traffic to a more manageable 5Gbps over the slowest link. Of course this also slows down the rate of recovery.
These have to be set on every OSD host in /etc/ceph/ceph.conf under the [osd] section.
osd_recovery_max_active: 1 # (default 3) osd_backfill_scan_min: 8 #(def 64) osd_backfill_scan_max: 64 #(def 512) osd_recovery_sleep_hybrid: 0.1 # (def .0125)
We tested this during backfill to a single node which would normally completely saturate this network link. Putting these settings in place on every OSD had the effect of reducing traffic to about 5Gbps with the additional effects of slowing down our recovery operations: as seen in the plots below.
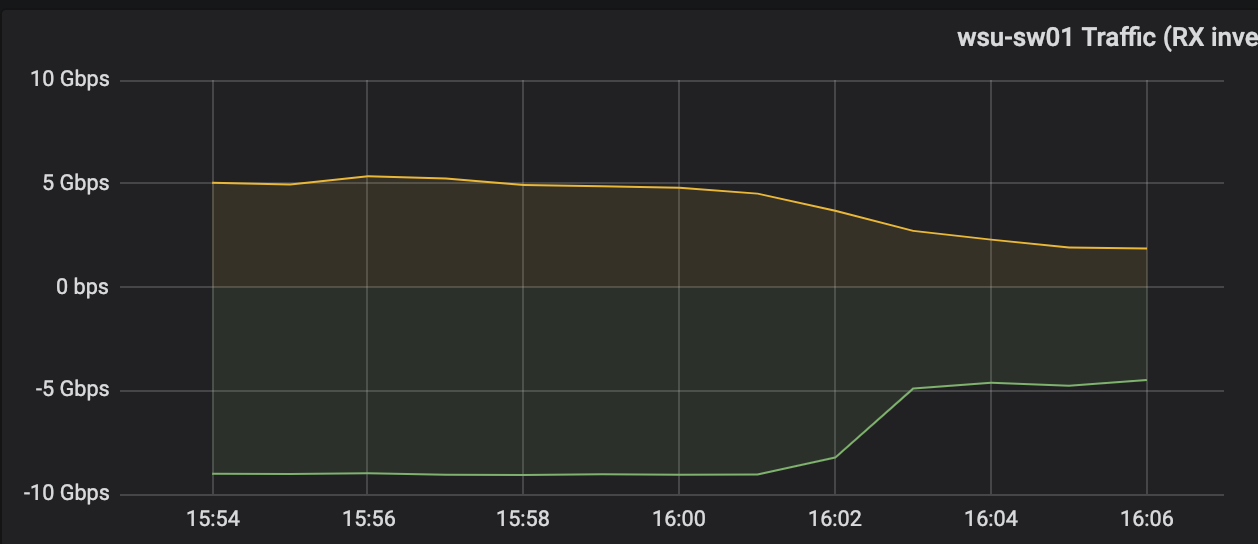 Effect of recovery settings on network bandwidth usage
Effect of recovery settings on network bandwidth usage
 Effect of recovery settings recovery operations
Effect of recovery settings recovery operations
The trade-off is acceptable as otherwise we would see operational issues during backfill like this.
More information on these settings is available from Ceph OSD documentation
Ceph and Network Latency
One of our project goals is to explore the limits of Ceph and our distributed architecture. As such we did extensive simulated latency testing.
We also did real-world latency testing at Supercomputing 2016. As a method to work around network latency we have also explored and are actively using Ceph cache tiering functionality. Experiments with this were done at Supercomputing 2016, Supercomputing 2018, and we have deployed a production cache tier at the Van Andel Institute in Grand Rapids, MI.
The Ceph CRUSH map also allows for choosing which OSD will be used as the primary in any given set of replicas, and the primary is where reads/writes are directed. Setting the primary to be proximate to where most client reads will occur can boost performance (for those clients) in a high-latency deployment. Our article details the configuration and performance benchmarks.