Setting Primary OSD For Read Optimization
Michael Thompson, Wayne State University
 Image from Ceph architecture documentation
Image from Ceph architecture documentation
OSiRIS introduces a new variable to Ceph with the respect to placement of data containers (placement groups or PG) on data storage devices (OSD). Ceph by default stores redundant copies on randomly selected OSDs within failure domains defined by the CRUSH map. Typically a failure domain is a host, rack, etc and PG replica have fairly low latency between each other.
The OSiRIS project is structured such that PG might be in different cities or even states with much higher network latency between them. This certainly effects overall performance but we do have some options to optimize for certain use cases. One of these options is setting our CRUSH rules to prefer one site or another for the Primary OSD when allocating PG copies. Based on our testing this is a great way to boost read I/O for certain use cases.
When a Ceph client reads or writes data it uses the CRUSH map to determine the primary OSD from among the available replication locations. This is then used directly to read or write data. The primary, unless strategically specified through the crush tree, is randomly selected by the CRUSH map from all available replication buckets. In a configuration like ours with copies spread across N locations the result is (N-1)/N of the all reads come from OSDs in non-proximate locations.
What if we have a case where most data usage occurs at a particular location? Obviously one solution is to allocate all the PG copies at that location - but then we can only leverage the storage at that location, and if there is an issue at the site the data is unavailable. Another solution is to modify the CRUSH map to prefer that site for the primary (first) OSD. All client direct I/O will come from the OSD at the site specified. Read operations will never hit the network latency of having to traverse to other sites as long as the primary is up. For write operations the client won’t have to communicate with offsite replicas but the OSD will need to replicate the write so there is much less effect on write I/O for this configuration.
Setting Primary OSD with CRUSH rules
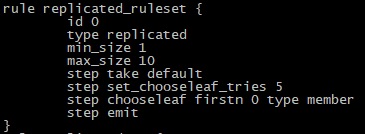 Typical CRUSH Rule allocating copies to OSiRIS 'member' sites (WSU,MSU,UM)
Typical CRUSH Rule allocating copies to OSiRIS 'member' sites (WSU,MSU,UM)
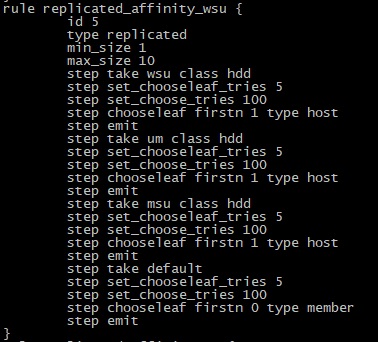 Example of a crush rule configured to optimize reads for WSU OSiRIS site
Example of a crush rule configured to optimize reads for WSU OSiRIS site
Results
At Supercomputing 2018 we applied this configuration using storage on the conference floor to host the primary OSD and compared it to reading from storage allocated with primary OSD at sites in Michigan.
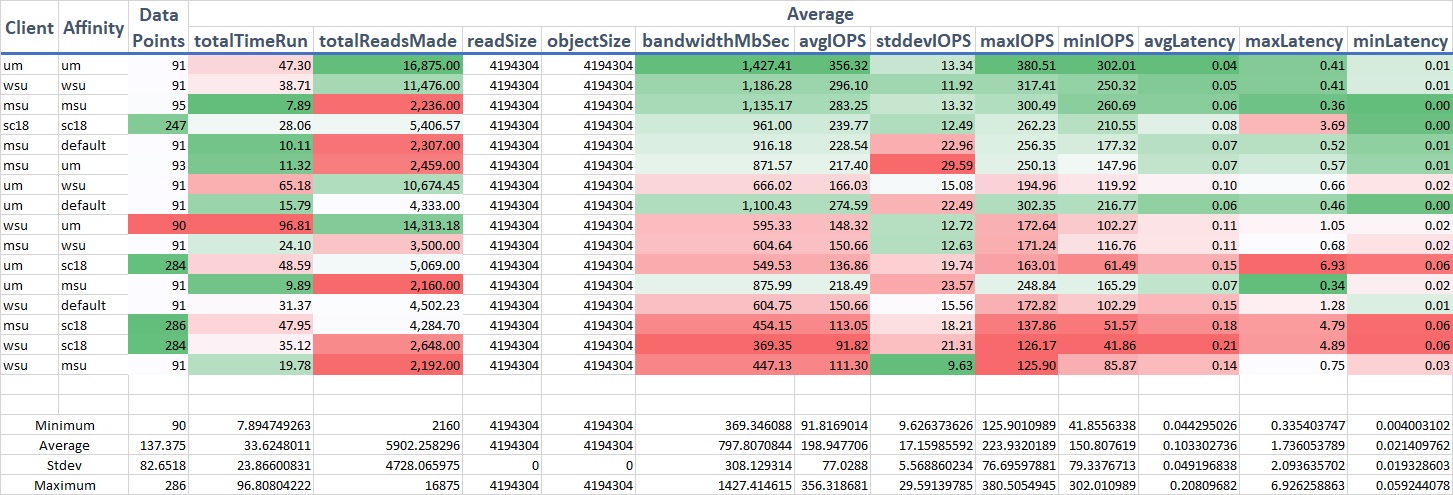 Benchmark results compared to using the default PG during Super Computing 2018
Benchmark results compared to using the default PG during Super Computing 2018We experienced reads between 400 MBytes/sec and 900 MBytes/sec when the operations included remote sites with higher latency (Dallas,TX to Michigan). When the primary OSD was mapped to the same location as the client we saw approximately 1,200 MBytes/sec. We continued this testing after SC and depending on the conditions at the time of test we would often see 100% improvement by setting the primary OSD closer to the client vs a random allocation at all three sites. The image above details all of these results.
Conclusion
Typically the architecture of Ceph is highly sensitive to latency between storage components. However, the flexibility of CRUSH maps does leave some room for optimization to avoid this issue. Adjusting the location of the primary OSD is one option that avoids having all copies of the data at one location while still giving that location a boost to read operations. It may also boost write operations to some extent but those are generally going to be still limited by the latency of replicating to offsite OSD. The obvious downside is that it also increases latency to clients not in proximity to the primary OSD. For some applications this particular set of tradeoffs may be a good fit.
OSiRIS also uses Ceph cache tiering to help work around latency issues. More information is linked below.
More Information
Working with the Ceph CRUSH Map
OSiRIS Ceph cache tiering benchmarks at SC18
OSiRIS cache tier deployment at Van Andel Institute
Tags