OSiRIS at the Van Andel Institute Leveraging Ceph Caching
OSIRIS at Van Andel Institute will enable VAI bioinformaticians to work with MSU researchers to better understand Parkinson’s disease and cancer, and will allow access to VAI researchers with MSU appointments to access the computational resources at ICER.
The OSiRIS site at Van Andel is deployed and managed similar to other OSiRIS sites. The 3 nodes there are part of the multi-institutional OSiRIS cluster and OSD are partitioned into a separate Ceph Crush tree to be used in rules defining cache tier pools.
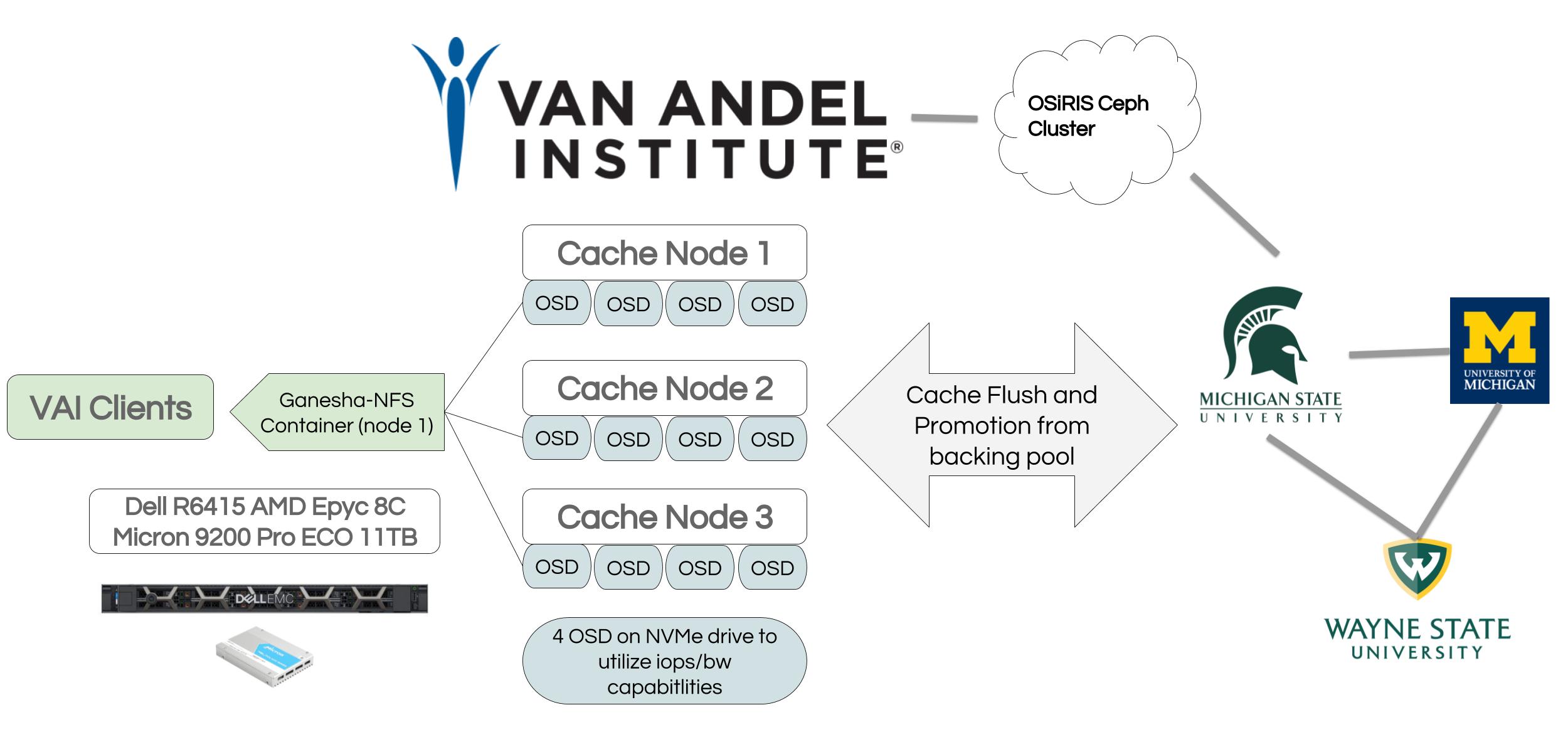
Clients at VAI (and elsewhere) will have reads and writes directed transparently through the Ceph cache tier pool located at their site.
One drawback of this configuration is the “and elsewhere”. Unfortunately Ceph does not offer a way to direct clients to the backing pool for data that is in sync with the cache. Clients not at Van Andel will see a marked reduction in performance due to their requests having to utilize the cache. This is understood and expected - the goal is to improve performance for VAI users within the limits of the cache while allowing for sufficient storage to keep data long term on the larger backing pool replicated on the other 3 OSiRIS sites.
Performance Benchmarking
Before moving this site into production we spent some time collecting benchmarks with this caching configuration using clients at Van Andel.
First a simple comparison using RADOS bench on a pool with a cache tier and one without.
Without cache overlay:
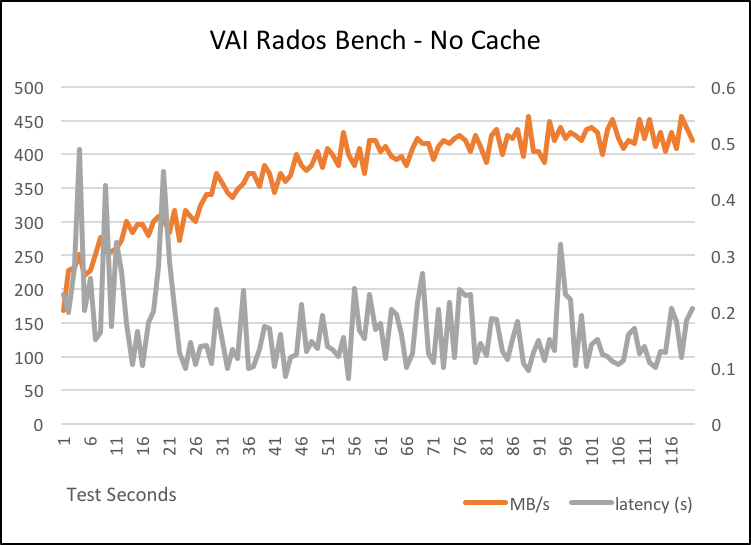
Total time run: 120.164 Total writes made: 11274 Write size: 4194304 Object size: 4194304 Bandwidth (MB/sec): 375.289 Stddev Bandwidth: 63.0688 Max bandwidth (MB/sec): 456 Min bandwidth (MB/sec): 168 Average IOPS: 93 Stddev IOPS: 15 Max IOPS: 114 Min IOPS: 42 Average Latency(s): 0.170519 Stddev Latency(s): 0.0805575 Max latency(s): 1.30727 Min latency(s): 0.0679402
The one with a cache tier we ran long enough to see the cache begin to flush. For this test the cache max_bytes setting was intentionally set quite low so it began to flush sooner. You can see a slight reduction in throughput when objects start to flush.
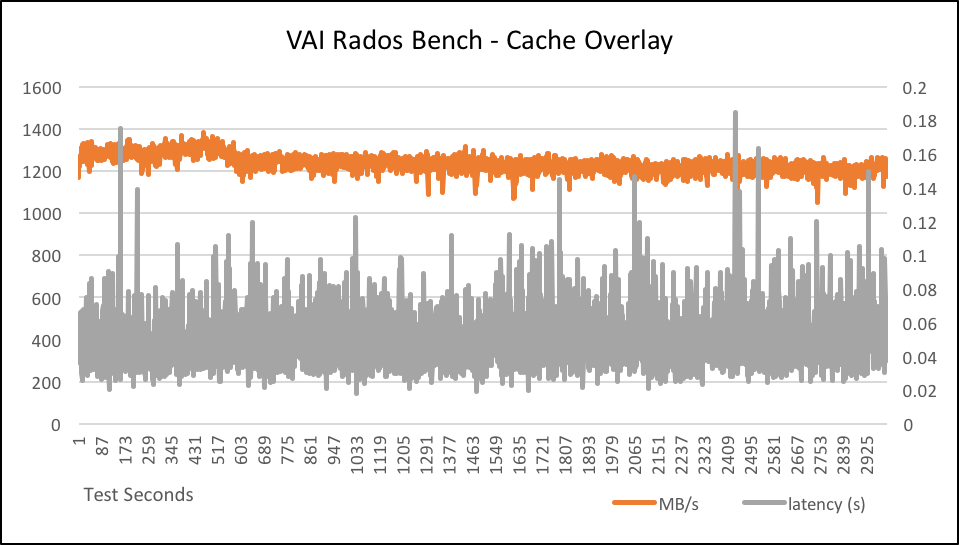
Total time run: 3000.04 Total writes made: 926281 Write size: 4194304 Object size: 4194304 Bandwidth (MB/sec): 1235.02 Stddev Bandwidth: 39.1896 Max bandwidth (MB/sec): 1384 Min bandwidth (MB/sec): 1052 Average IOPS: 308 Stddev IOPS: 9 Max IOPS: 346 Min IOPS: 263 Average Latency(s): 0.0518185 Stddev Latency(s): 0.0174813 Max latency(s): 0.46436 Min latency(s): 0.0168139
Here is a snapshot of Ceph pool usage during this test as well. The pool cou.VAI.fs is the backing pool replicated at the 3 non-VAI sites (UM, MSU, WSU). The pool cou.VAI.fs.cache is the cache overlay pool replicated on the three nodes at VAI.

Configuration Details
As a first step, when initializing OSD on the VAI nodes we had the following in ceph.conf to place them correctly in our Crush hierarchy. It’s important that they come up outside the default tree to avoid data being replicated to them. Details here may vary depending on default crush rules - perhaps a cluster could have a default rule to use devices in class hdd so a new device in class ssd will not be used by the default replication rules.
crush_location = root=cache host=vai-stor-nvc01 rack=vai-rack building=vai-gr member=vai
Once everything is online and OSD initialized we end up with a crush tree as follows:
-77 30.01904 root cache -76 30.01904 member vai -91 30.01904 building vai-gr -74 30.01904 rack vai-rack -88 10.00635 host vai-stor-nvc01 387 ssd 2.50159 osd.387 up 1.00000 1.00000 393 ssd 2.50159 osd.393 up 1.00000 1.00000 397 ssd 2.50159 osd.397 up 1.00000 1.00000 399 ssd 2.50159 osd.399 up 1.00000 1.00000 -75 10.00635 host vai-stor-nvc02 405 ssd 2.50159 osd.405 up 1.00000 1.00000 409 ssd 2.50159 osd.409 up 1.00000 1.00000 413 ssd 2.50159 osd.413 up 1.00000 1.00000 417 ssd 2.50159 osd.417 up 1.00000 1.00000 -73 10.00635 host vai-stor-nvc03 372 ssd 2.50159 osd.372 up 1.00000 1.00000 376 ssd 2.50159 osd.376 up 1.00000 1.00000 380 ssd 2.50159 osd.380 up 1.00000 1.00000 384 ssd 2.50159 osd.384 up 1.00000 1.00000
Note: We manage Ceph configuration and OSD initialization using a Puppet module
Create replicated crush rule named ‘vai-cache’ with crush root ‘vai’, failure domain ‘host’ and using only ‘ssd’ device classes. The SSD specification is not strictly required since there are no other classes of device under the vai root.
ceph osd crush rule create-replicated vai-cache vai host ssd
Create pool following our typical naming scheme with 512 PG. With only 12 OSD more PG doesn’t make sense and just creates undue load on the OSD hosts. More information and a calculator: https://ceph.com/pgcalc/
ceph osd pool create cou.VAI.fs.cache 512 512 replicated vai-cache
Assign the pool to be a cache pool overlaying the VAI CephFS pool in writeback mode (vs read-only mode). As far as the docs indicate there is only one hit_set_type but you have to set it or the cluster will generate a warning.
ceph osd tier add cou.VAI.fs cou.VAI.fs.cache ceph osd tier cache-mode cou.VAI.fs.cache writeback ceph osd tier set-overlay cou.VAI.fs cou.VAI.fs.cache ceph osd pool set cosbench_cache_tier hit_set_type bloom
The following settings for cache flushing are actually the defaults (except max bytes). We may lower the flush percentages to ensure the cache keeps more free space available - the link back to other OSiRIS sites is fairly slow (4Gb) so our final numbers depend on whether we need to optimize more as a write cache or to keep more hot data in the cache.
ceph osd pool set cou.VAI.fs.cache target_max_bytes 9901930829414 # % of max_bytes_full to start flushing dirty objects ceph osd pool set cou.VAI.fs.cache cache_target_dirty_ratio .3 # when to flush harder ceph osd pool set cou.VAI.fs.cache cache_target_dirty_high_ratio .4 # also start evicting clean objects ceph osd pool set cou.VAI.fs.cache cache_target_full_ratio .7