OSiRIS and SLATE at SC18 Storage and Edge services demo
![]()
SLATE (Services Layer At The Edge) aims to provide a platform for deploying scientific services across national and international infrastructures. At SC18 they demonstrated their containerized Xcache service using a 50 TB Rados Block Device hosted by OSiRIS in a pool overlaid by our Ceph cache tier at SC18.
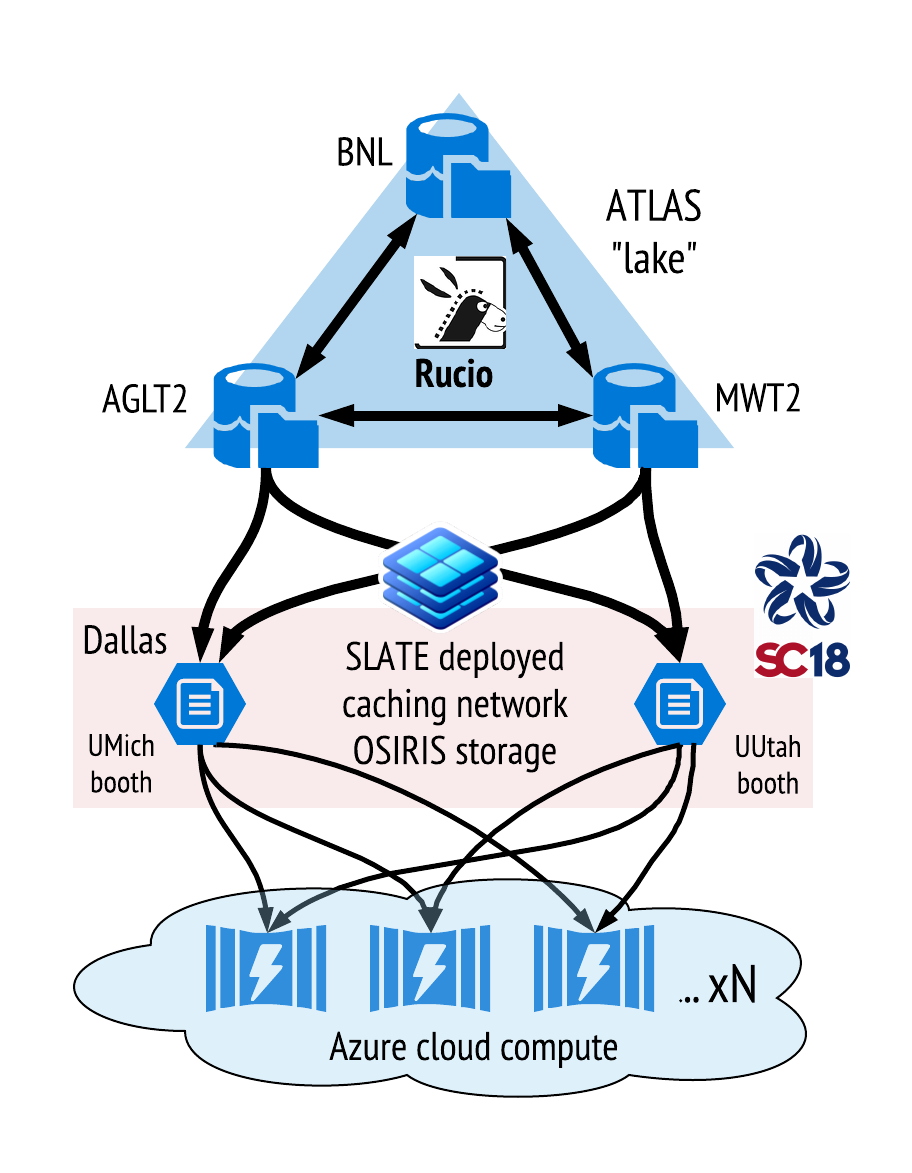 SLATE demo overview
SLATE demo overview
- Demo high throughput xcache service on SLATE platform at two nodes.
- Cloud based clients read from ATLAS “lake” through cache.
- Payload data are replay of MWT2 production accesses in August.
For OSiRIS this usage provided an opportunity for experience with RBD devices overlaid with a cache tier as well as a stress test for accessing cache tier devices hosting multiple tier pools for multiple access methods. In addition to the SLATE RBD cache pool our tier storage hardware also had mapped to it a pool for RGW, CephFS, and RADOS.
Layers of Cache
The SLATE group also leveraged local NVMe storage in combination with ZFS to improve read and write performance beyond what a network device is capable of. This configuration is readily applicable to a variety of RBD workloads with or without a cache tier involved.
- 3 SSDs attached as “L2ARC” (Level 2 Adaptive Replacement Cache) - improves reads
- 1 SSD attached as ZIL (ZFS Intent Log) - improves writes
- As the RBD is a network block device, ZFS needed various tunings
- Pool needed alignment shift (4k sectors), record size (1MB), no atime / directory atime
- In the kernel driver we increased the # of parallel IOs to the block device by a 5-10x to take advantage of Ceph’s concurrency
- L2ARC max write speed increased from 8MB/s -> 512MB/s to fill the local NVMe cache faster
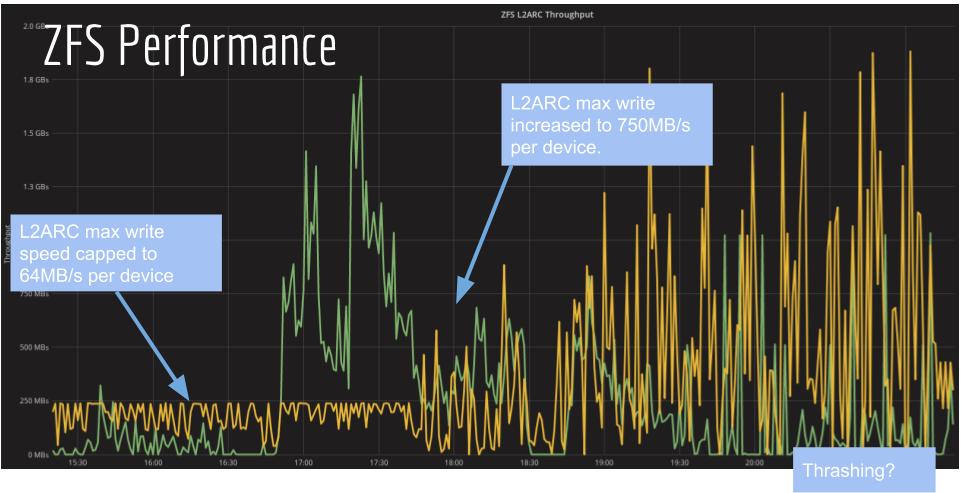 ZFS + Ceph RBD Throughput
ZFS + Ceph RBD Throughput
OSiRIS Cache Behaviour
From the OSiRIS perspective the behaviour of the cache was somewhat predictable - but that’s good! We didn’t encounter any issues and the plots of RBD device throughput when compared to the Ceph pool throughput generally indicate that the RBD usage stayed entirely within the cache at SC18. We see some cache flushing to the backing pool but this was transparent to the RBD device in terms of performance impact. As far as we are concerned this very well demonstrates that a cache like this is an excellent fit for bringing higher performance to locations with higher latency to our primary storage elements.
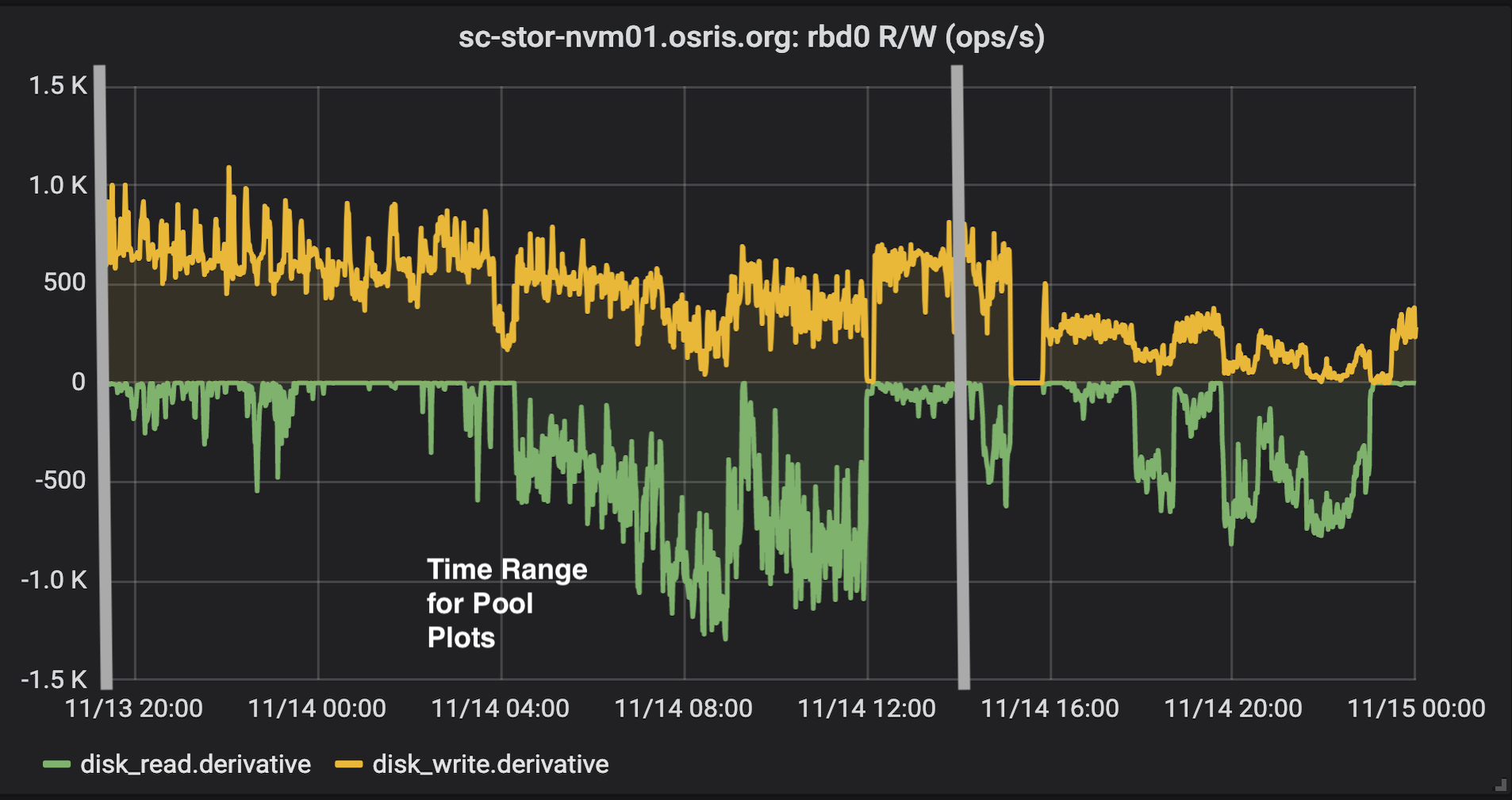 SLATE RBD Ops/S
SLATE RBD Ops/S
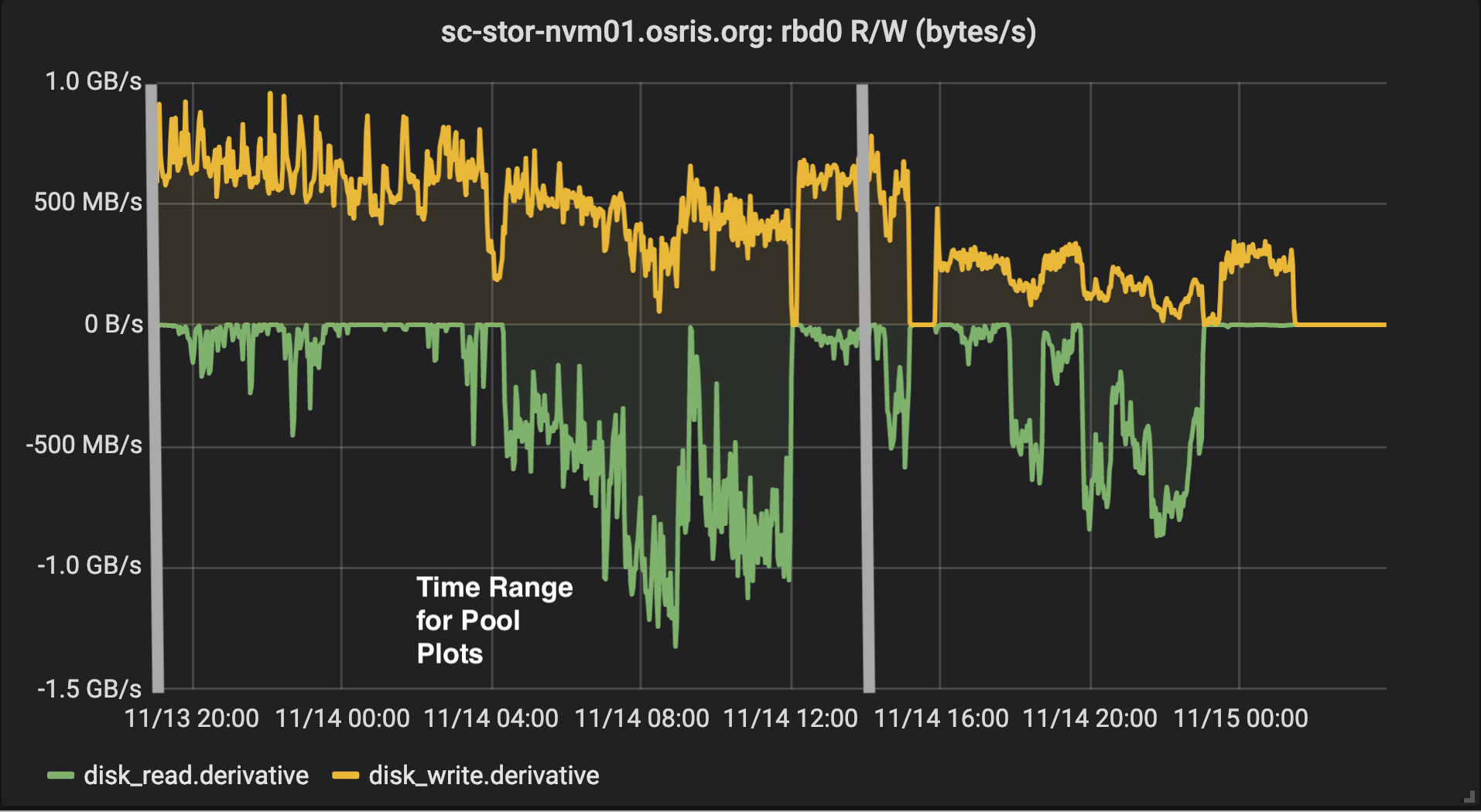 SLATE RBD Throughput
SLATE RBD Throughput
The plots below of pool throughput and bytes used verify our RBD device is doing I/O entirely to the cache tier while the cache tier is busily flushing objects to the backing pool.
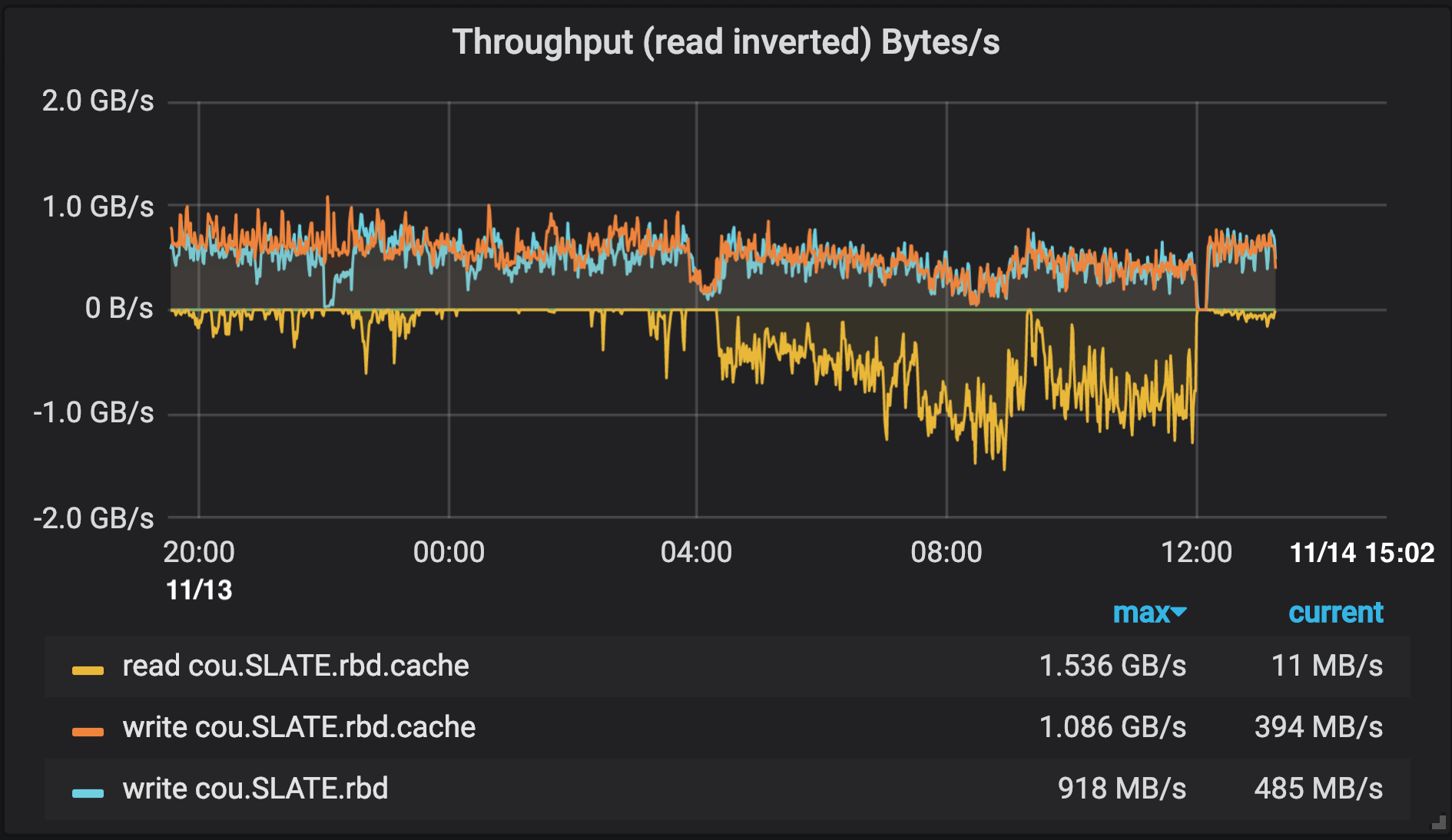 OSiRIS SLATE RBD pool throughput - reads all coming from cache, flushing ongoing in background (blue line)
OSiRIS SLATE RBD pool throughput - reads all coming from cache, flushing ongoing in background (blue line)
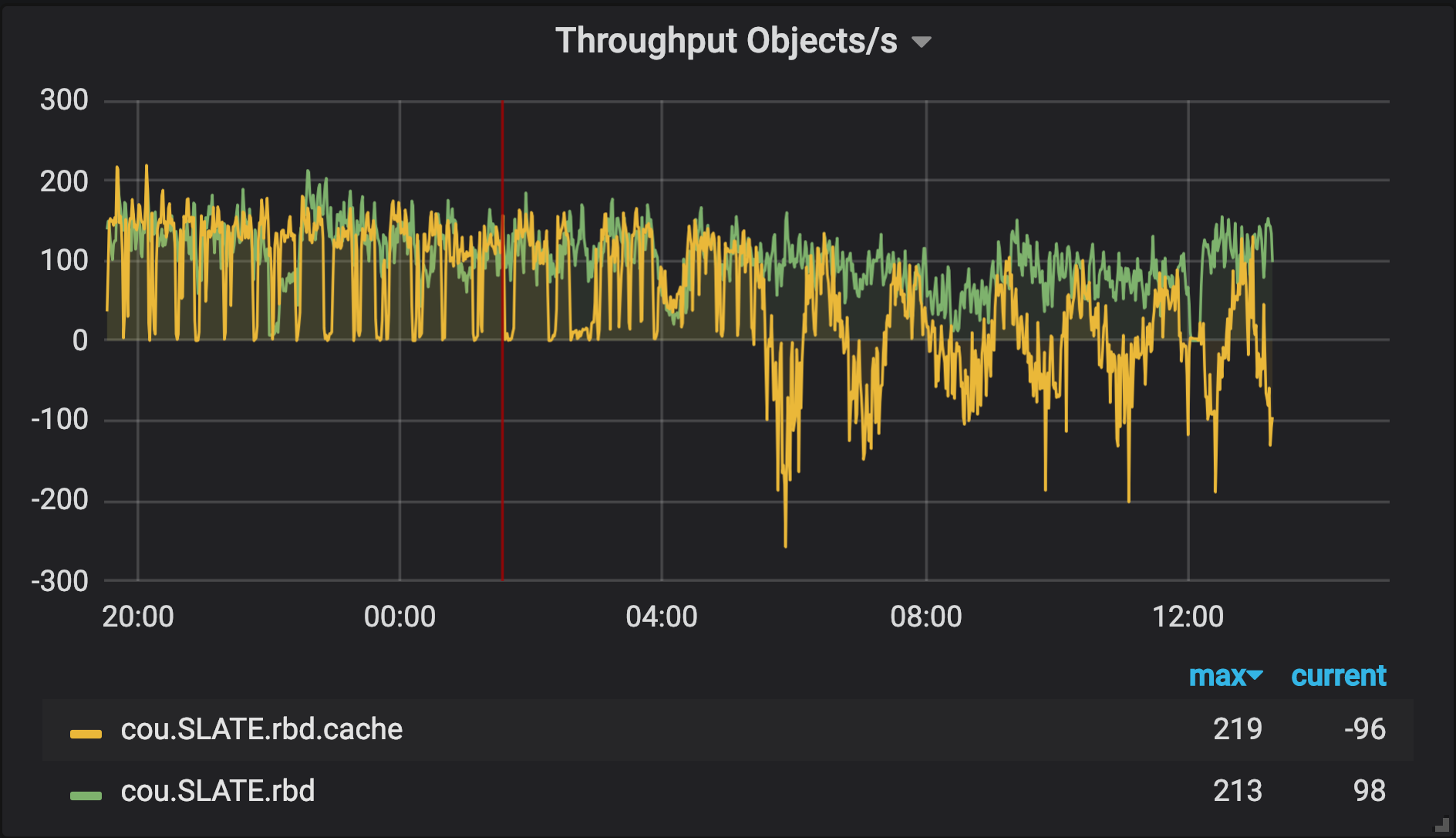 OSiRIS SLATE RBD pool objects / second - negative values indicate objects being removed from cache (presumably inactive data being flushed)
OSiRIS SLATE RBD pool objects / second - negative values indicate objects being removed from cache (presumably inactive data being flushed)
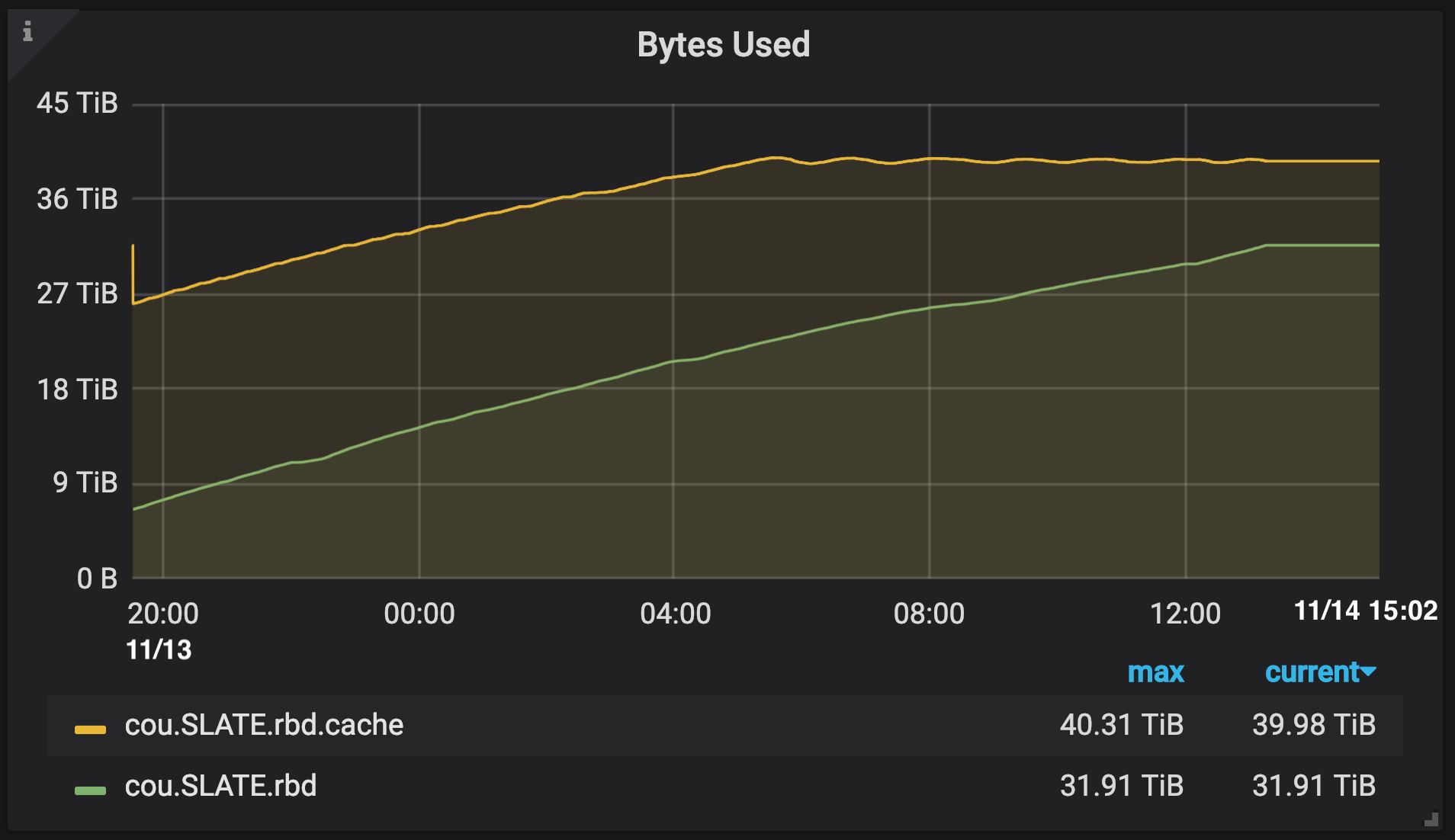 OSiRIS SLATE RBD pool bytes - shows cache flushing to backing pool
OSiRIS SLATE RBD pool bytes - shows cache flushing to backing pool
Setup
To begin with we create two pools. One is our standard COU (virtual org) pool created by our COmanage Ceph Provisioner. This pool is by default replicated to our 3 main storage sites at UM, MSU, and WSU. The 2nd pool is the cache pool which we want to be replicated only on hosts at Supercomputing.
When we configured our OSD node at Supercomputing we configured it to be in a separate CRUSH root in the node ceph.conf:
crush_location = root=supercomputing host=sc-stor-dmd01 rack=crate-1 building=kbh-center member=sc
Our default CRUSH rule starts at root ‘default’ under which all of the ‘members’ reside and thus it would have replicated all of our data pools to the new node.
Given that CRUSH location we then create a rule which allocates PG only to nodes under the supercomputing root:
ceph osd crush rule create-replicated sc18-hdd-replicated supercomputing osd hdd
Finally we create our cache tier pool:
ceph osd pool create cou.SLATE.rbd.cache 1024 1024 replicated sc18-hdd-replicated
Then we can proceed to add the new tier pool as an overlay to the cou.SLATE.rbd backing pool in write-back mode:
~]# ceph osd tier add cou.SLATE.rbd cou.SLATE.rbd.cache pool 'cou.SLATE.rbd.cache' is now (or already was) a tier of 'cou.SLATE.rbd' ~]# ceph osd tier cache-mode cou.SLATE.rbd.cache writeback set cache-mode for pool 'cou.SLATE.rbd.cache' to writeback ~]# ceph osd tier set-overlay cou.SLATE.rbd cou.SLATE.rbd.cache overlay for 'cou.SLATE.rbd' is now (or already was) 'cou.SLATE.rbd.cache'
You have to set the hit_set_type (though there is only one option)
~]# ceph osd pool set cou.SLATE.rbd.cache hit_set_type bloom set pool 251 hit_set_type to bloom
We also need to set a maximum number of bytes for the pool. This will be used by the various _ratio settings and to stop I/O to the pool when it reaches the limit. You want to ensure the pool will stop I/O before it overfills OSD.
~]# ceph osd pool set cou.SLATE.rbd.cache target_max_bytes 54975581388800 set pool 251 target_max_bytes to 54975581388800
The following numbers for dirty and full ratio are the defaults. They seemed to make sense for our application where we would like to have the cache mostly full (high full_ratio) but do need to ensure there is space for any writes to avoid waiting for the lower latency link back to Michigan (lower dirty_ratio). If we really wanted to aggressively make sure there is writable space in the cache we would set lower ratios but the SLATE xcache is a read-heavy application once it has written enough data to operate as an effective cache.
~]# ceph osd pool get cou.SLATE.rbd.cache cache_target_dirty_ratio cache_target_dirty_ratio: 0.4 ~]# ceph osd pool get cou.SLATE.rbd.cache cache_target_full_ratio cache_target_full_ratio: 0.8 ~]# ceph osd pool get cou.SLATE.rbd.cache cache_target_dirty_high_ratio cache_target_dirty_high_ratio: 0.6
More on Cache Tiering
Ceph cache tier documentation: http://docs.ceph.com/docs/mimic/rados/operations/cache-tiering
OSiRIS Van Andel Cache Tier setup: https://www.osris.org/domains/vai.html
OSiRIS Cache tiering tests at SC18 (rgw,fs,rados): Ceph Cache Tiering Demo
Tags