Cache Tier Demo at SC18
 Demo Equipment
Demo Equipment
At Supercomputing 2018 the OSiRIS project configured a Ceph storage node with 60 OSD to host cache tier pools. This gave us approximately 600TB of raw caching space, or 200TB with 3x replicated pools. For purposes of testing we replicated pools on just a single host but in a production setup a more resilient set of OSD would be desirable.
Below is an overview of the setup:
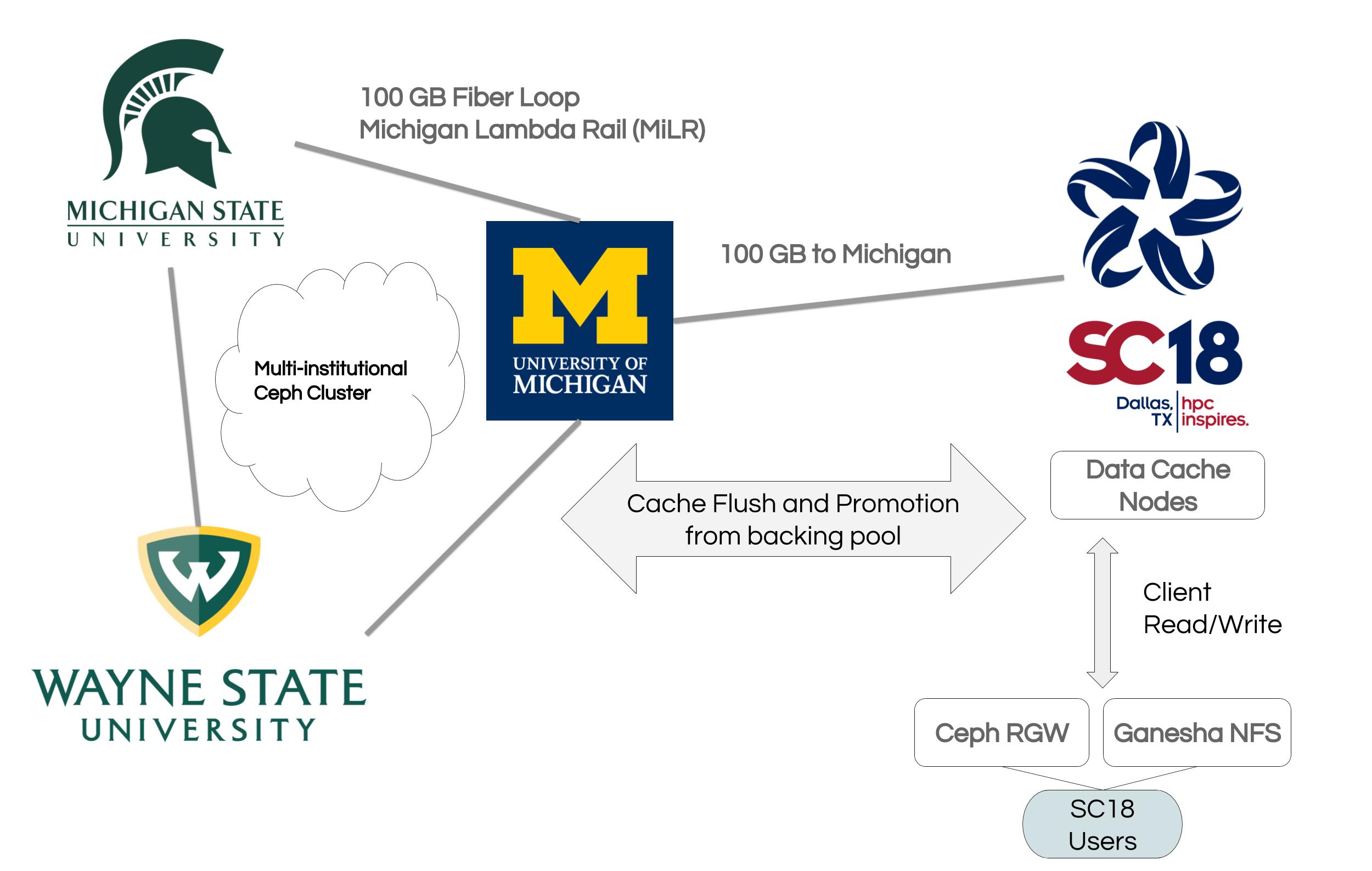
We used the SC18 node to host cache overlays for Radosgw, CephFS, and direct Rados.
A 2nd node at SC hosted gateway or client services - Ganesha NFS and Radosgw. For Ganesha we used version 2.6 from our Docker image. Radosgw was configured to use the new Beast frontend in Mimic. Typically we run HAproxy in front of several instances but for this event we just ran one standalone.
Normally with a Ceph client geographically far away from the Ceph OSD it is expected that higher latency decreases IOPS and overall throughput. The latency between Dallas and our sites in Michigan is about 25ms. The latency between our sites in Michigan is more like 2-3ms and latency between hosts in the same datacenter is less than 1ms.
The performance hit from latency is extremely obvious when communicating with the cluster directly via RADOS. Below is a plot showing Latency, IOPS and Throughput averages. The tests labeled ‘Michigan Storage’ use a pool on OSD in Michigan (WSU/MSU/UM). The tests labeled ‘SC18 Cache’ use a pool also located in Michigan but with a cache tier overlaid which is using OSD at SC18. During the duration of the test the cache tier does not flush back to Michigan.
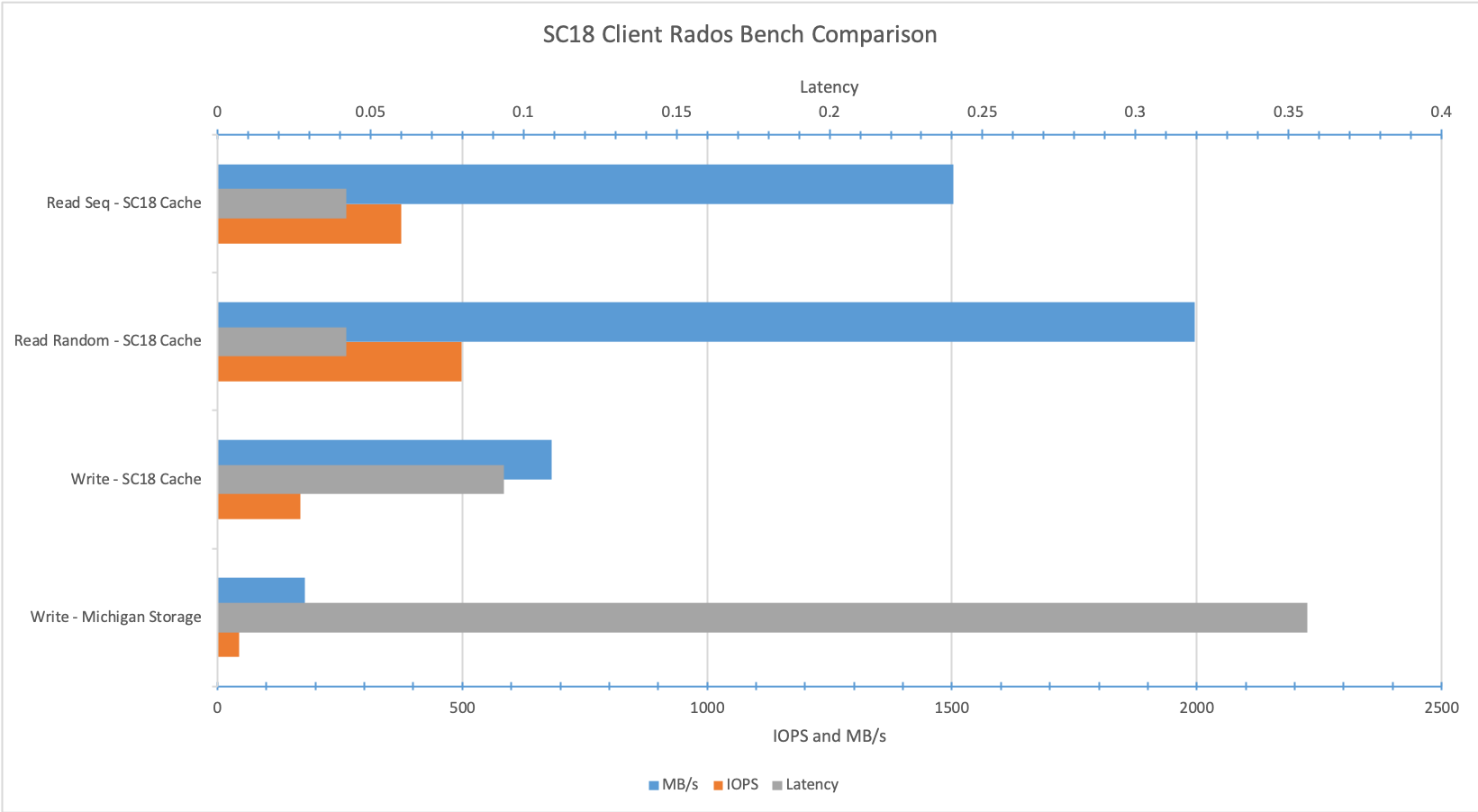 Rados bench average with and without cache tier, 120s duration test
Rados bench average with and without cache tier, 120s duration test
The differences here are fairly obvious and dramatic. Reducing the latency for client communications greatly increases the numbers. With a large enough cache one could reasonably keep enough ‘hot’ data that latency delays would be rare. Unfortunately other unrelated issues invalidated the results during a read test from the Michigan storage pool but the result would most likely be slower than similar tests with cache tier as with the write test.
But we also did some tests with other services. Below are the results from running tests with swift bench. We tried 4 scenarios here all using a swift-bench client at SC18:
- RGW service at SC18, using cache overlay at SC18
- RGW service in Michigan, using cache overlay at SC18. The idea here was to see how great a penalty is incurred when clients in Michigan are forced to direct writes through a far-away cache tier. The Michigan RGW service is backed by 3 RGW instances behind HAproxy.
- RGW service at SC18 using pool in Michigan with no cache overlay
- RGW service in Michigan using pool in Michigan with no cache overlay
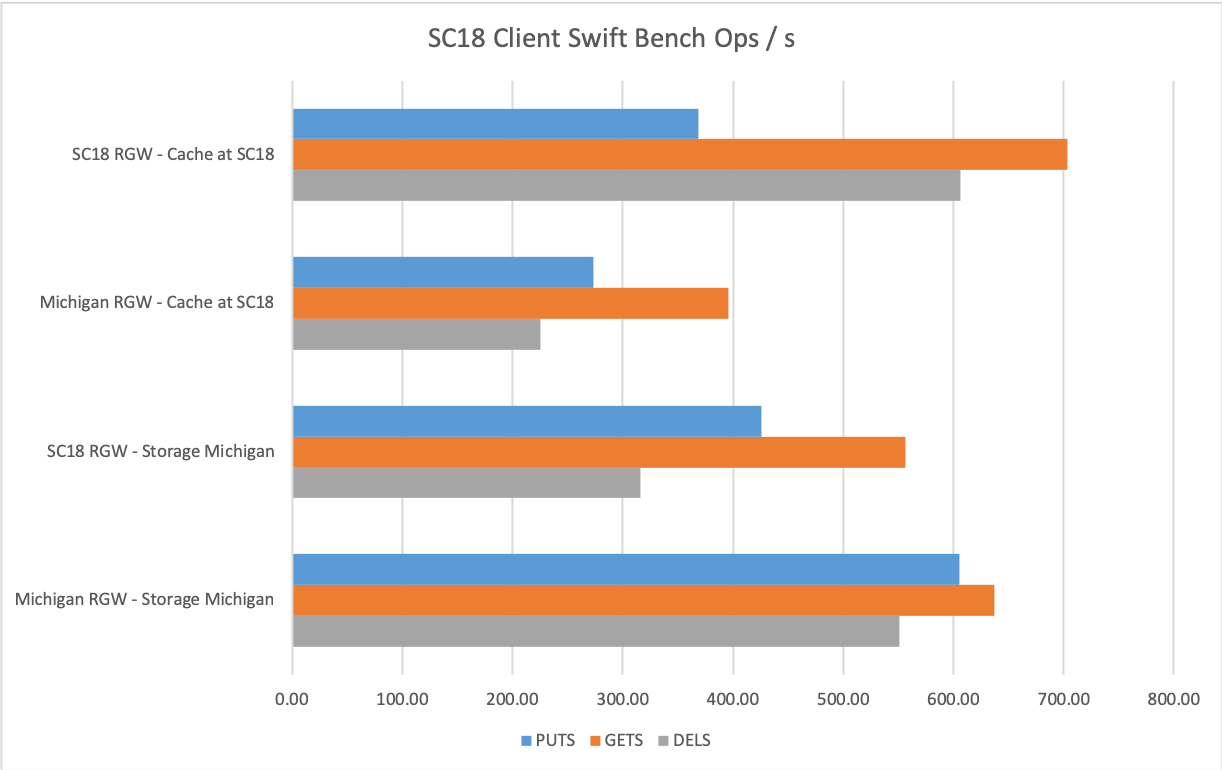 Swift bench average with and without cache tier
Swift bench average with and without cache tier
Our flags to swift bench were:
-c 32 (number of concurrent connections -s 8192 (object size max bytes) -l 512 (object size lower limit) -n 50000 (number of objects to put) -g 50000 (number of gets)
The differences here are visible as well. The RGW instance at SC18 predictably does higher ops/s when utilizing the cache tier. One anomaly is the slightly higher PUT ops for the SC18 RGW utilizing storage placed back in Michigan. This figure is an average and both tests hit similar peaks during the run so I think we can attribute this to some other factor and call them approximately equal with the upper limit determined by the capabilities of a single radosgw instance.
Another thing we notice is that the SC18 swift client bench achieves a higher rate of PUTS/s when using the Michigan RGW installation with Michigan storage. This is most likely because there are more RGW instances processing requests behind this endpoint URL. Noting as well the fairly small difference in GETS and DELS between SC18 RGW with cache (top test) and Michigan RGW (bottom test) it seems that the latency between client and RGW endpoint is not much of a factor as it is with RADOS itself. This may be unsurprising given that Rados clients communicate more directly with storage elements involved but useful to document nonetheless.
We also deployed a Ganesha NFS instance using the Ceph FSAL and ran iozone tests against directories placed on pools with and without cache tier. In this case there is almost no difference between the results - it looks like the NFS stack is caching these ops since the files are relatively small. There seems only to be a slight boost to writes at higher record sizes.
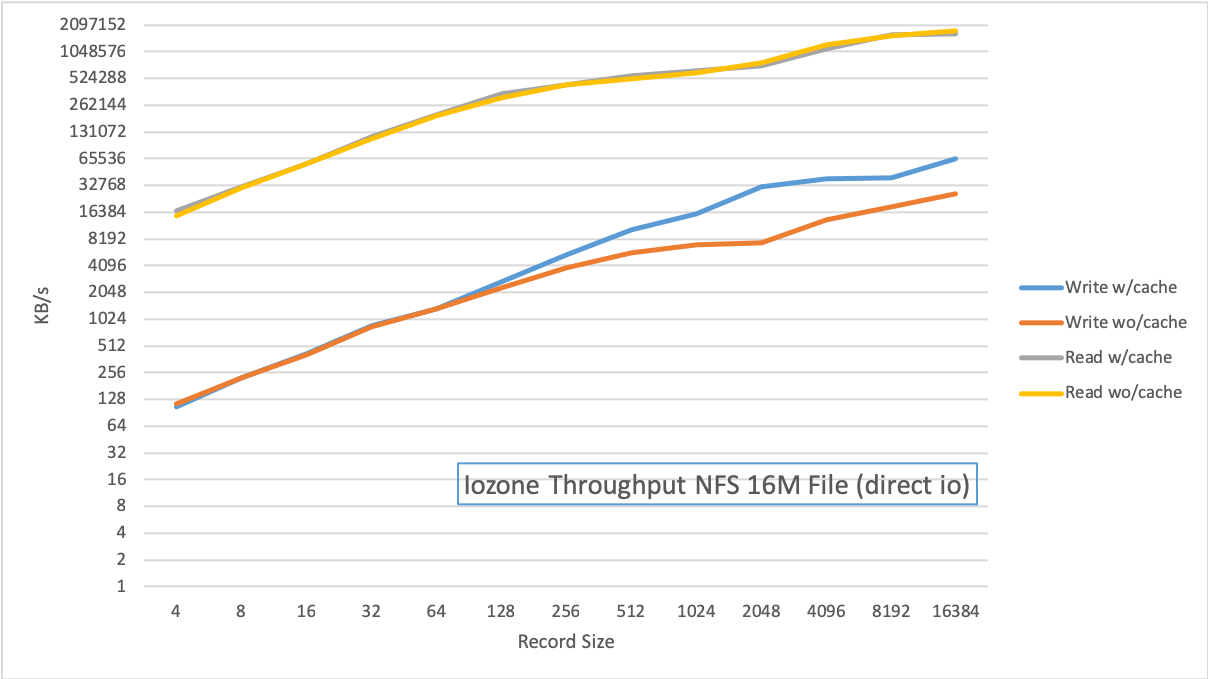 IOZone throughput results with and without cache tier
IOZone throughput results with and without cache tier
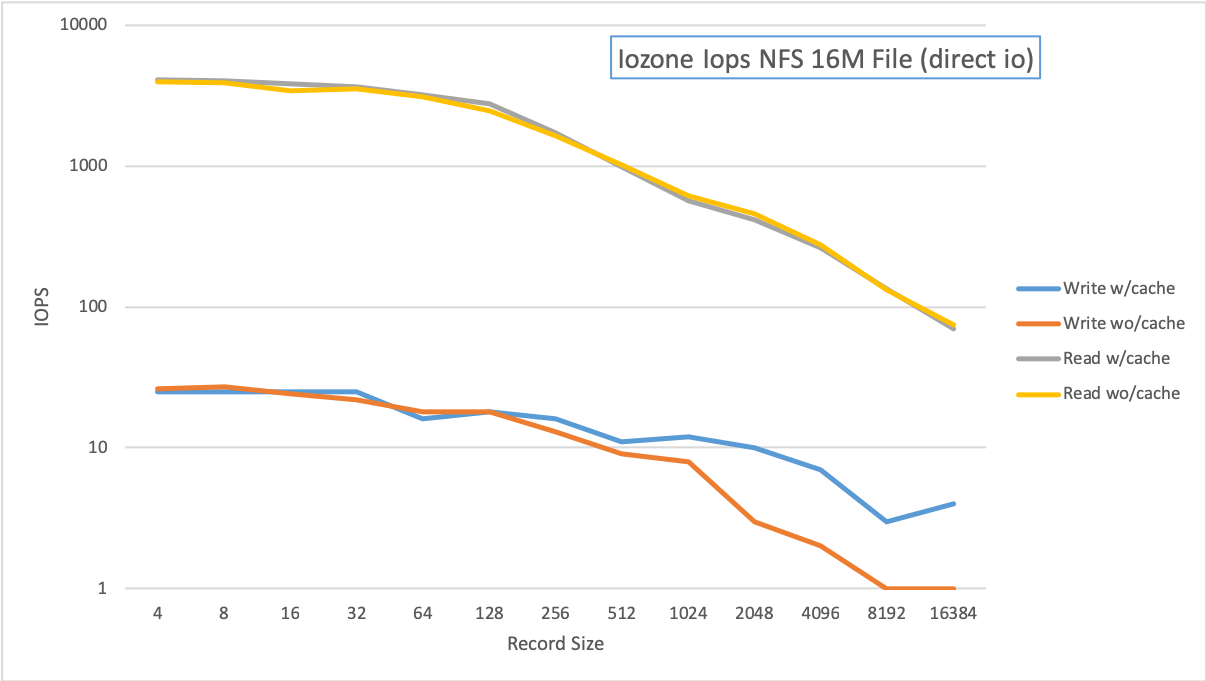 IOZone IOPS results with and without cache tier
IOZone IOPS results with and without cache tier
Given the similarity of results it’s worth verifying that the test pools were configured and utilized as expected. We can see this on the plots collected from ceph-mgr via the influxdb module.
These plots align with the tests as follows:
22:23 iops/cache, 1:44 througput/cache, 3:42 iops/nocache, 6:01 throughput/nocache
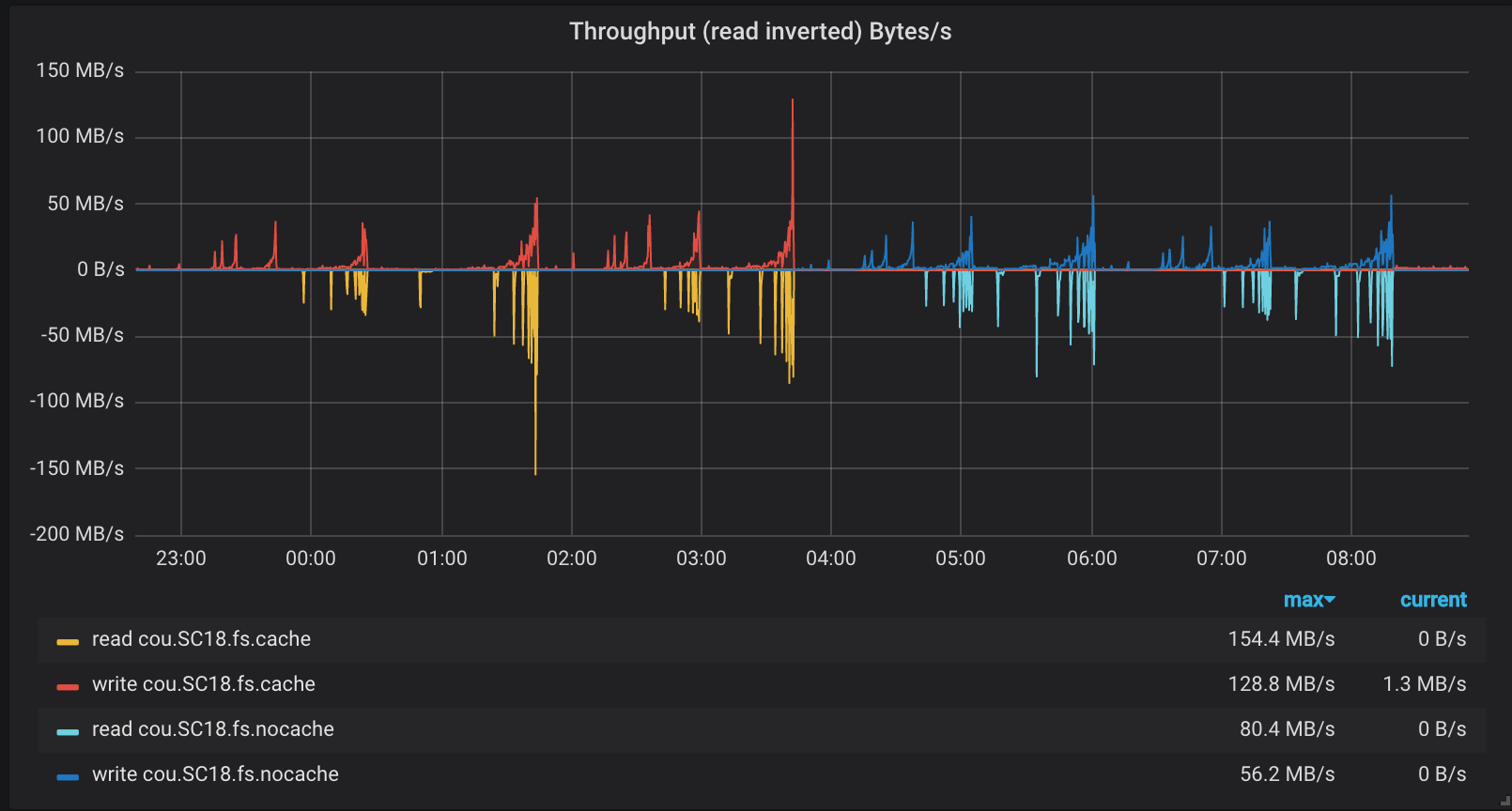 Pool data throughput
Pool data throughput
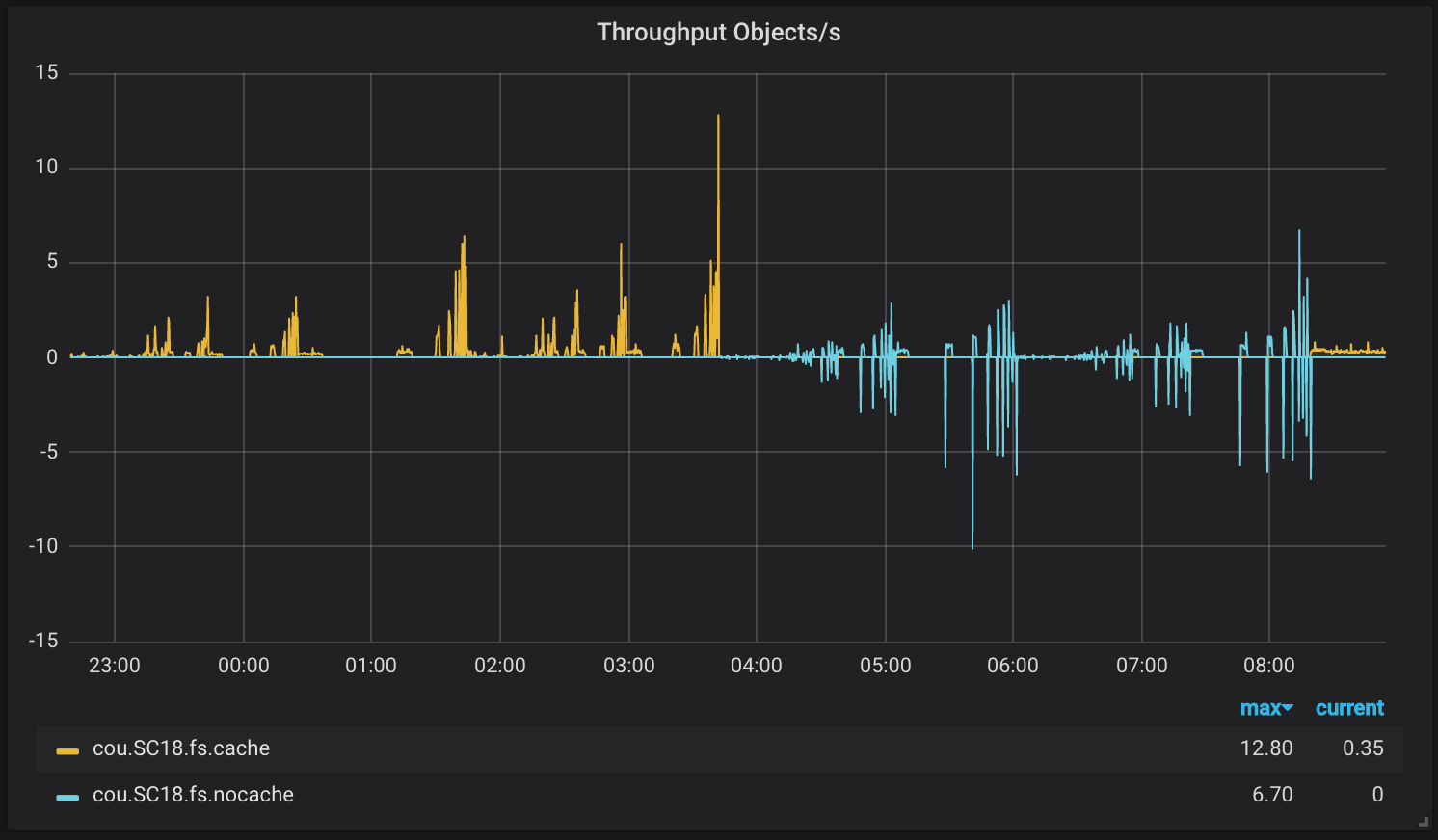 Pool objects written (negative is objects removed)
Pool objects written (negative is objects removed)
As you can see the pool utilization is different depending which directory the tests were utilizing and is consistent with our expectations for using or not using cache pools.
Conclusions
These tests show that in general there is a quite significant boost for rados clients when a high-latency pool is overlaid with a cacher tier having much lower latency to the client. Likewise there is a benefit if the radosgw service has lower latency to a cache tier. Less significant is the latency between S3/Swift client and RGW instance - in fact we saw that having more RGW instances working on requests produced higher PUTS / Second than a single instance even with more latency between the client and RGW instances.
Where we saw much less benefit or difference was with NFS exports. However our benchmarks do show that as files are written with larger block sizes the cache tier does begin to play a role in increasing IOPS and Throughput. Most likely if we had done tests with larger file sizes we’d see a greater effect here.
A cache tier arrangement like this is not relevant to every use case. In fact it has significant disadvantages for users who might see higher latency to the cache components but lower latency to the main storage pool. For the right use case it can make a lot of sense and allow for small storage installations backed by the resources of the entire OSiRIS project.
Setup Notes
When we configured our OSD node at Supercomputing we configured it to be in a separate CRUSH root in the node ceph.conf:
crush_location = root=supercomputing host=sc-stor-dmd01 rack=crate-1 building=kbh-center member=sc
Our default CRUSH rule starts at root ‘default’ under which all of the ‘members’ reside and thus it would have replicated all of our data pools to the new node.
Given that CRUSH location we then create a rule which allocates PG only to nodes under the supercomputing root:
ceph osd crush rule create-replicated sc18-hdd-replicated supercomputing osd hdd
Finally we create our cache tier pool (different pools for each app used above) as an overlay to the normal virtual organization pools (aka COU) created by our COmanage Ceph Provisioner. These pools are by default replicated to our 3 main storage sites at UM, MSU, and WSU.
ceph osd pool create cou.SC18.rgw.cache 1024 1024 replicated sc18-hdd-replicated ceph osd pool create cou.SC18.fs.cache 1024 1024 replicated sc18-hdd-replicated ceph osd pool create cou.SC18.rados.cache 1024 1024 replicated sc18-hdd-replicated
Then we can proceed to add the new tier pools as an overlay to the cou.SC18.xx backing pools in write-back mode. Just one example is show below:
ceph osd tier add cou.SC18.rgw cou.SC18.rgw.cache pool 'cou.SC18.rgw.cache' is now (or already was) a tier of 'cou.SC18.rgw' ceph osd tier add cou.SC18.rgw cou.SC18.rgw.cache pool 'cou.SC18.rgw.cache' is now (or already was) a tier of 'cou.SC18.rgw' ceph osd tier cache-mode cou.SC18.rgw.cache writeback set cache-mode for pool 'cou.SC18.rgw.cache' to writeback ceph osd tier set-overlay cou.SC18.rgw cou.SC18.rgw.cache overlay for 'cou.SC18.rgw' is now (or already was) 'cou.SC18.rgw.cache' ceph osd pool set cou.SC18.rgw.cache hit_set_type bloom set pool 257 hit_set_type to bloom
We then have to set a maximum bytes target for the pool. I/O to the cache pool will stop until it can flush some data if this target is reached. We want to set a figure that will avoid over-filling OSD and stopping I/O for that reason. In this particular context we also have several cache pools being hosted at SC18 so we set a size, taking replicated size into consideration, that will not fill our host even if all the cache pools are at max bytes.
ceph osd pool set cou.SC18.rgw.cache target_max_bytes 54975581388800 set pool 257 target_max_bytes to 54975581388800
Given the above max_bytes we choose dirty and clean flush ratios. The defaults are 0.4, 0.7, 0.8. We bumped them up just a little higher to prefer keeping the cache a little more full - our usage at SC18 is not likely to fill it up. One might choose lower numbers if having available space to cache writes is more important than avoiding a read from the backing pool.
Of course there’s a lot of different use interactions that might decide the best ratios - read heavy, write heavy, sporadic writes or more constant, etc. Since we’re using a cache to overcome latency issues there is a different set of considerations vs using one to overlay faster storage on top of slower. In fact the cache tier docs note that using a tier for the latter case usually is not going to improve performance very much.
ceph osd pool set cou.SC18.rgw.cache cache_target_dirty_ratio .5 set pool 257 cache_target_dirty_ratio to .5 ceph osd pool set cou.SC18.rgw.cache cache_target_dirty_high_ratio .7 set pool 257 cache_target_dirty_high_ratio to .7 ceph osd pool set cou.SC18.rgw.cache cache_target_full_ratio .9 set pool 257 cache_target_full_ratio to .9
More on Cache Tiering
Ceph cache tier documentation: http://docs.ceph.com/docs/mimic/rados/operations/cache-tiering
OSiRIS Van Andel Cache Tier setup: https://www.osris.org/domains/vai.html
SC18 SLATE RBD Cache tiering collaboration: OSiRIS and SLATE at SC18
Tags